
Keeping up with a fast-moving industry like AI is difficult. So, until AI can do it for you, here's a helpful summary of recent stories in the world of machine learning, along with notable research and experiments that we didn't cover on our own.
This week on AI I'd like to highlight startups in the tagging and annotation space — startups like Scale AI, which is reportedly in talks to raise $13 billion in new funds. Tagging and annotation platforms may not get the attention that shiny new generative AI models like Sora from OpenAI do. But it is necessary. Without it, modern AI models would arguably not exist.
The data that many models are trained on must be labeled. Why? Labels or tags help models understand and interpret data during the training process. For example, labels for training an image recognition model might take the form of labels around objects, “bounding boxes,” or captions that indicate each person, place, or object depicted in the image.
The accuracy and quality of labels greatly affect the performance and reliability of the trained models. Annotation is a huge task, requiring thousands and millions of labels for the larger and more sophisticated datasets used.
So you might think that data annotators would be treated well, paid a living wage, and given the same benefits as engineers who build the models themselves. But more often than not, the opposite is true – a product of the harsh working conditions fostered by many annotation and taxonomy startups.
Companies with billions in the bank, like OpenAI, relied on interpreters in Third World countries for just a few dollars an hour. Some of these commenters are exposed to extremely disturbing content, such as graphic images, yet are not given leave (because they are usually under contract) or access to mental health resources.
An excellent article in NY Mag pulls back the curtain on Scale AI in particular, which is recruiting commentators in countries as far away as Nairobi and Kenya. Some tasks at Scale AI require raters to have multiple eight-hour work days — with no breaks — and pay as little as $10. These workers are beholden to the whims of the platform. Sometimes bloggers go long periods without getting work, or are unceremoniously kicked out of Scale AI — as happened to contractors in Thailand, Vietnam, Poland, and Pakistan recently.
Some annotation and labeling platforms claim to provide “fair trade” work. They've made it a core part of their brand in fact. But as MIT's Kate Kay notes, there is no regulation, only weak industry standards for what it means to do ethical labeling — and companies' definitions vary widely.
So what to do? Barring a massive technological breakthrough, the need to annotate and classify data to train AI is not going away. We can hope that these platforms will self-regulate, but the more realistic solution seems to be policy-making. This in itself is a difficult prospect, but it is the best chance we have to change things for the better. Or at least start doing so.
Here are some other noteworthy AI stories from the past few days:
OpenAI is building a voice cloner: OpenAI is previewing a new AI-powered tool it has developed, Voice Engine, that enables users to clone audio from a 15-second recording of someone speaking. But the company has chosen not to deploy it widely (yet), citing the risks of misuse. Amazon doubles down on Anthropic: Amazon has invested an additional $2.75 billion in growing AI powerhouse Anthropic, following up on an option it left open last September. Google.org Launches Accelerator: Google.org, the philanthropic wing of Google, is launching a new $20 million, six-month program to help fund nonprofits developing technology that leverages generative artificial intelligence. New Model Architecture: AI startup AI21 Labs has released a generative AI model, Jamba, that uses a new(ish) model architecture — state space models, or SSMs — to improve efficiency. Databricks launches DBRX: In other modeling news, Databricks this week released DBRX, a generative AI model similar to OpenAI's GPT series and Google's Gemini. The company claims to have achieved state-of-the-art results on a number of popular AI benchmarks, including several measurement methods. Uber Eats and AI regulation in the UK: Natasha writes about how Uber Eats' fight against AI bias shows that achieving fairness under UK AI regulations is hard to come by. EU Election Security Guidance: The European Union published draft election security guidelines on Tuesday aimed at those around them Two dozen Platforms regulated under The Digital Services Act, including guidelines on preventing content recommendation algorithms from spreading AI-based disinformation (also known as political deepfakes). Grok Upgraded: X's Grok chatbot will soon get an upgraded base model, Grok-1.5 – meanwhile, all premium subscribers on X will have access to Grok. (Grok was previously exclusive to X Premium+ customers.) Adobe expands Firefly: Adobe this week unveiled Firefly Services, a collection of more than 20 new and innovative APIs, tools, and services. It has also launched Custom Forms, which allows businesses to fine-tune Firefly forms based on their assets – part of Adobe's new GenStudio suite.
More machine learning
How is the weather? Artificial intelligence is increasingly able to tell you this. I noticed some efforts in 24/7 and century forecasting a few months ago, but like all things AI, this field is moving quickly. The teams behind MetNet-3 and GraphCast have published a paper describing a new system, called SEEDS, for the Scalable Envelope Diffusion Sampler.
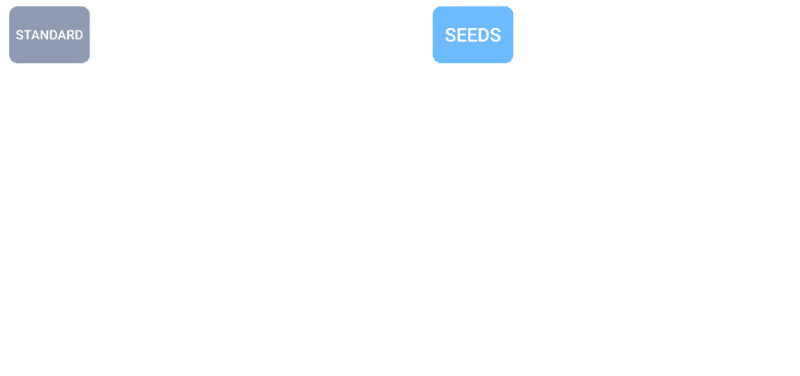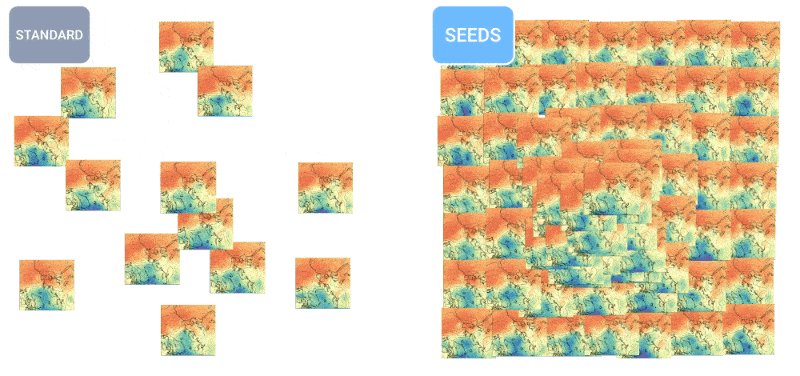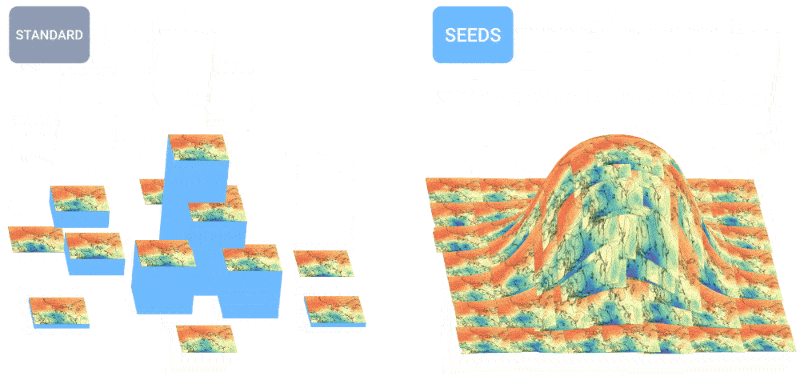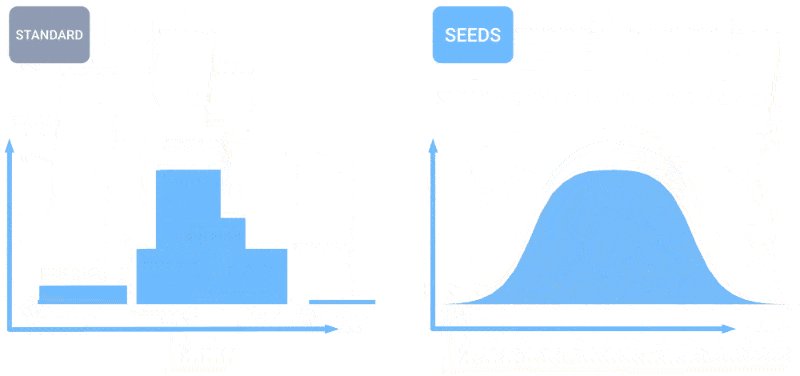
An animation showing how more forecasts lead to a more balanced distribution of weather forecasts.
SEEDS uses diffusion to generate “sets” of plausible weather outcomes for an area based on inputs (radar readings or orbital images perhaps) much faster than physics-based models. With larger numbers of groups, they can cover more edge cases (such as an event that only occurs in 1 out of 100 possible scenarios) and be more confident about which situations are more likely.
Fujitsu also hopes to better understand the natural world by applying AI image processing techniques to underwater images and lidar data collected by autonomous underwater vehicles. Improving the quality of images will allow other, less complex operations (such as 3D conversion) to work better on the target data.
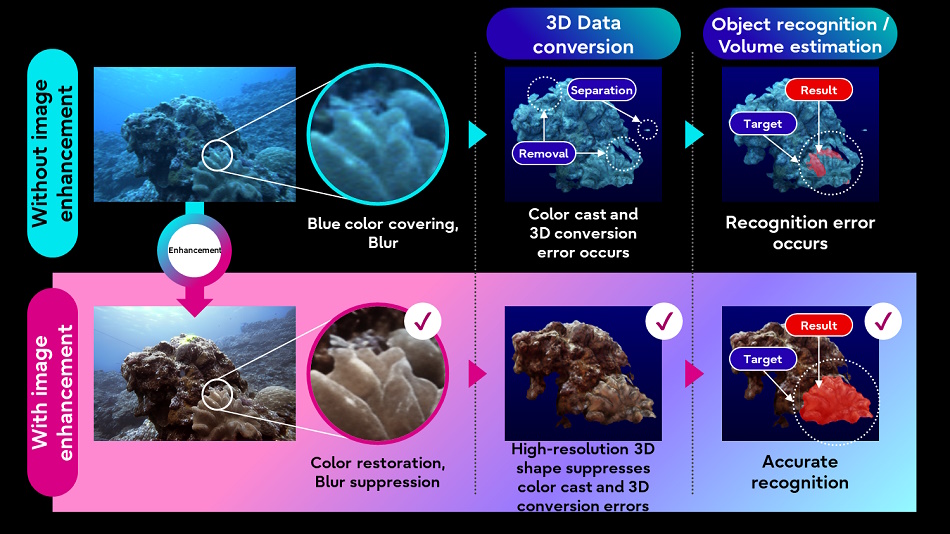
Image credits: Fujitsu
The idea is to build a “digital twin” of water that can help simulate and predict new developments. We are a long way from that, but you have to start somewhere.
Among LLM holders, researchers found that they modeled intelligence in a simpler way than expected: linear functions. Honestly, the math is beyond my capabilities (vector stuff in many dimensions) but this MIT article makes it very clear that the calling mechanism for these models is very simple.
Although these models are really complex, nonlinear functions that are trained on a lot of data and are difficult to understand, sometimes there are really simple mechanisms at work within them. “This is one example of that,” said co-lead author Ivan Hernandez. If you're more interested in the technical stuff, check out the paper here.
One way these models can fail is by not understanding the context or feedback. Even really able LLM students may not “get it” if you tell them your name is pronounced a certain way, because they don't actually know or understand anything. In cases where this might be important, such as human-robot interactions, it could turn people away if the robot behaved in this way.
Disney Research has been looking into robotic interactions between characters for a long time, and name pronunciation and paper reuse have been around for a while. It seems obvious, but extracting phonemes when someone introduces themselves and encoding that instead of just their written name is a smart approach.

Image credits: Disney Research
Finally, as AI and research become more and more intertwined, it is worth re-evaluating how these tools are being used and whether there are any new risks presented by this unholy union. Safia Umoja Noble has been an important voice in the field of AI and research ethics for years, and her opinion has always been helpful. She gave a great interview with the UCLA News team about how her work has evolved and why we need to stay frozen when it comes to bias and bad habits in research.